
Literate DevOps
Maintaining servers falls into two phases: First, bang head until server works; second, capture effort into some automation tool like Puppet or Chef. Recently, I’ve been playing around with making the first phase closer to the second. For lack of a better word, I’m calling it literate devops.
I’ve talked about using org-mode’s literate programming model to investigate new ideas and crystallize thoughts, and this approach appears to work well for me, since I lack those esoteric sysadmin skills.
Tell us a Story
Once upon a time, I was tasked with patching an RPM. Clearly, not in my comfort zone, so my initial plan of attack was:
- Use Vagrant to create a disposable CentOS system
- SSH into this virtual machine and to download and run commands
- Rinse and repeat step #2 until successful
First step is pretty easy and well documented elsewhere, but TIL
that you can use ssh directly to your Vagrant-based virtual
machine with this little magic:
vagrant ssh-config client >> $HOME/.ssh/config
Which appends some lovely host-connection magic. Goody.
Now comes the literate devops. Since I always have Emacs hosting
with my current sprint’s notes, so instead of opening up a terminal
to the virtual machine, I instead created a new header in my
org-mode file, and started entering the commands in the file.
What good is this? Well, it allows me to log, document and execute each command.
For instance, here is a screen-shot of a section of my Emacs buffer:
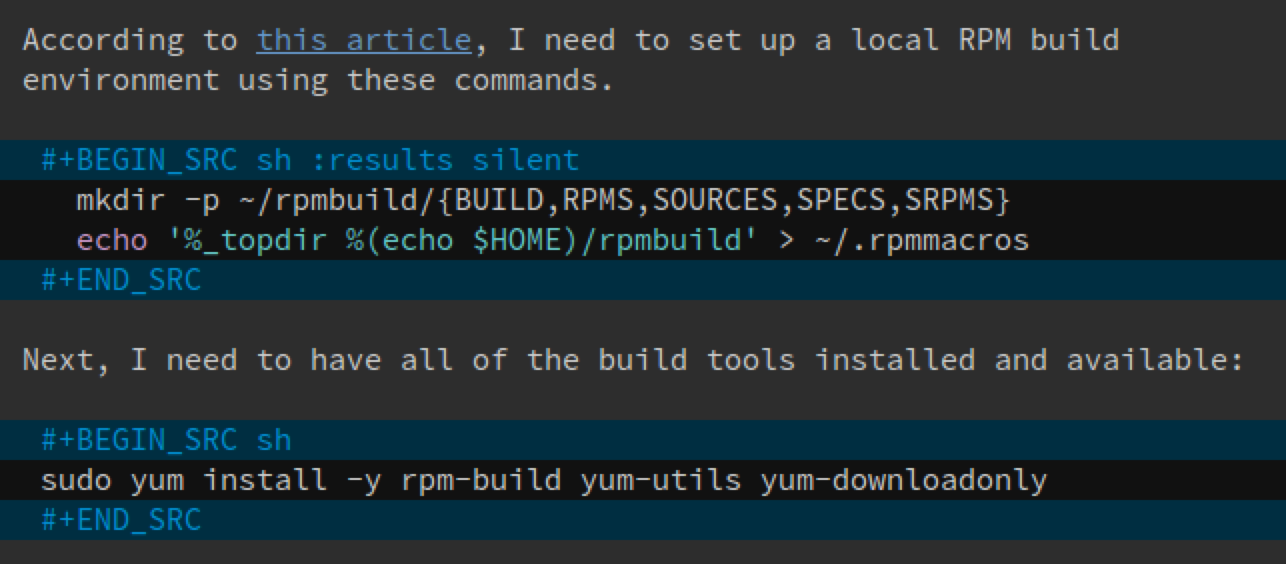
Clicking the hyperlink gives me the online details I discovered, and I can enter prose about each command, and I can execute the commands from within Emacs.
Yes. I can execute the commands from within Emacs.
Hitting C-c C-c (Control-C twice) runs the code based on the
language, and in this case, it runs it within my shell. The results
are placed back into the buffer or written to a file, and more.
What about the Virtual Machine?
Normally the sh bit tells Emacs to run it on my local system’s
shell, but in this case, I want it to run it on my virtual machine
(or even on my development server in my lab). I just run this little
bit of Emacs that include at the top of the file:
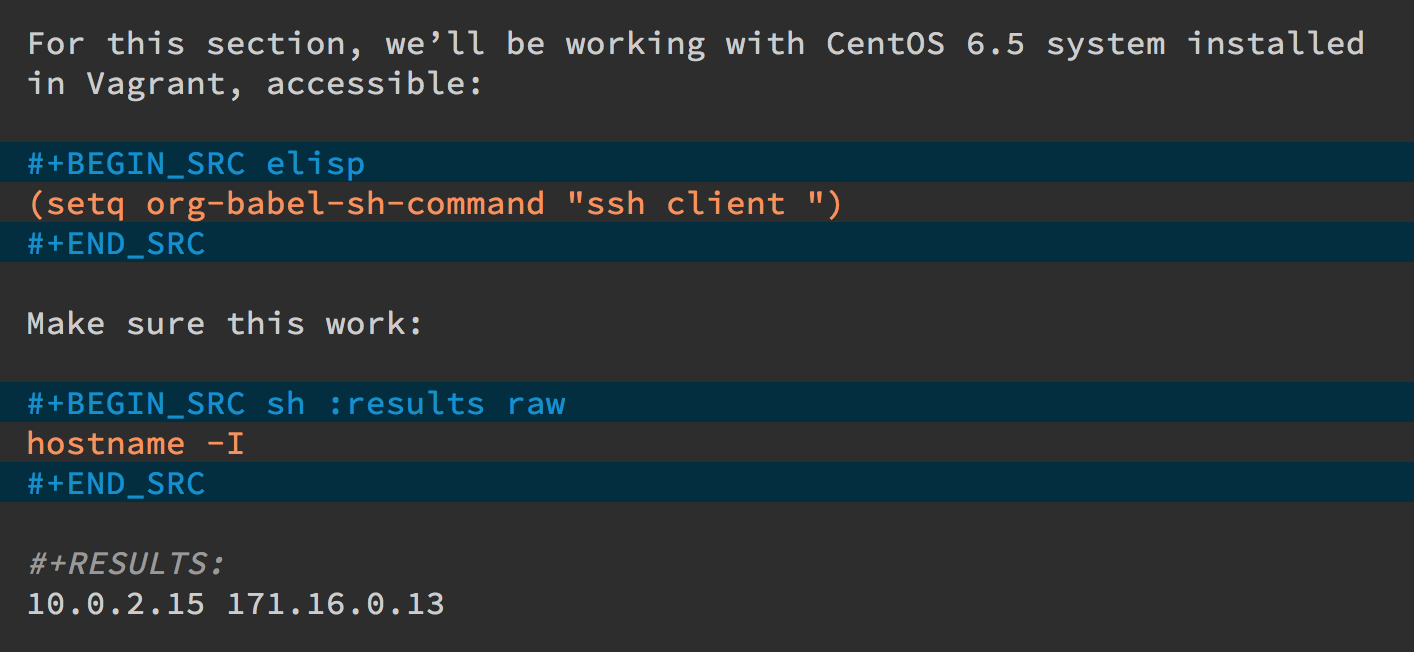
The first code block is some Emacs Lisp code that changes the
default command for executing sh code, and the second block I run
to see if it connects correctly.
Now, I can continue learning how to accomplish my target, all the while documenting and validating my steps. The end result can be exported to web or wiki page.
What about Verbose Commands?
Yes, some executing some commands can be quite time-consuming and verbose, but often I need to search the results, and having the results in an Emacs buffer allows me better searching.
Often I use a “drawer” (which is just a way to identify the beginning and end of the output:
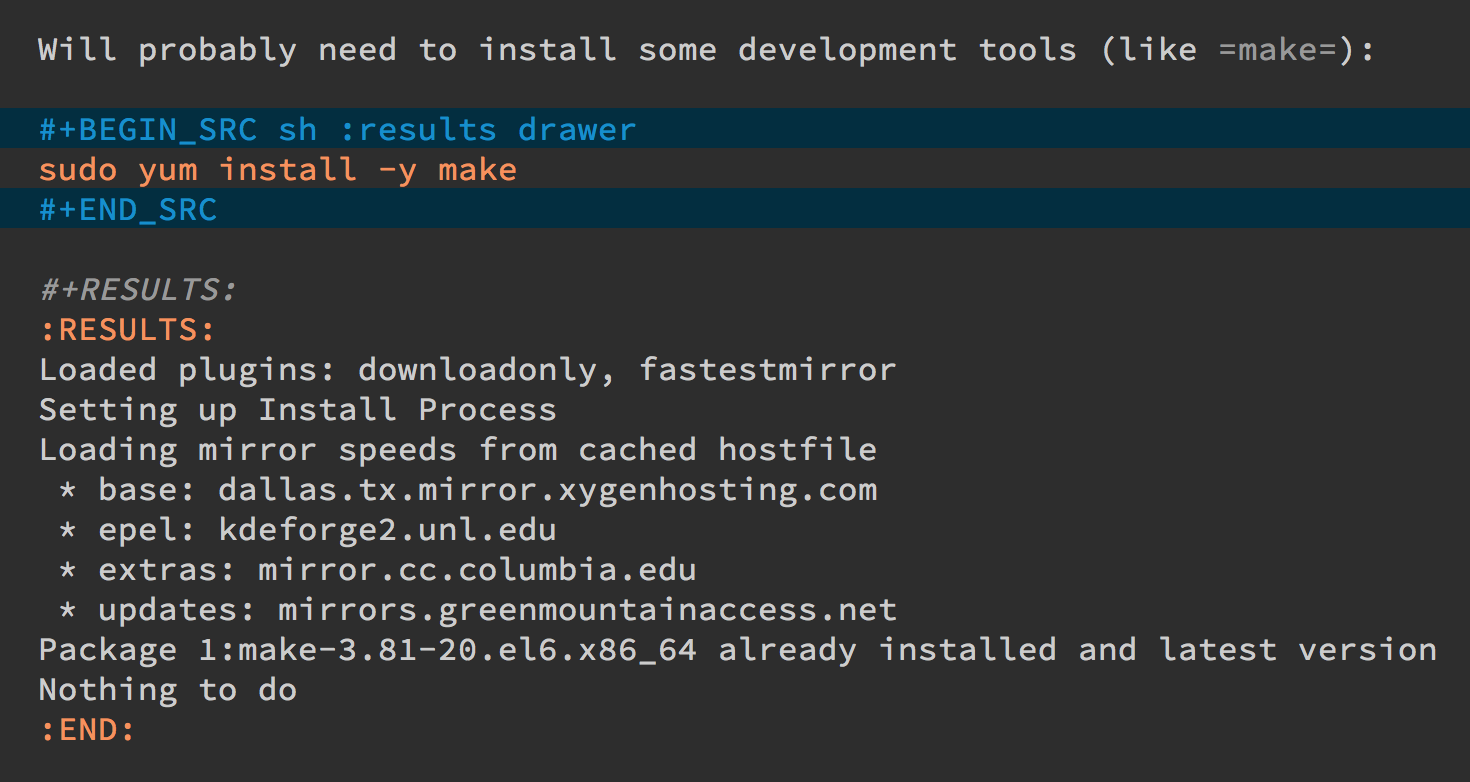
Which allows me to place the cursor of this drawer and hit the Tab
key to hide or show the output:
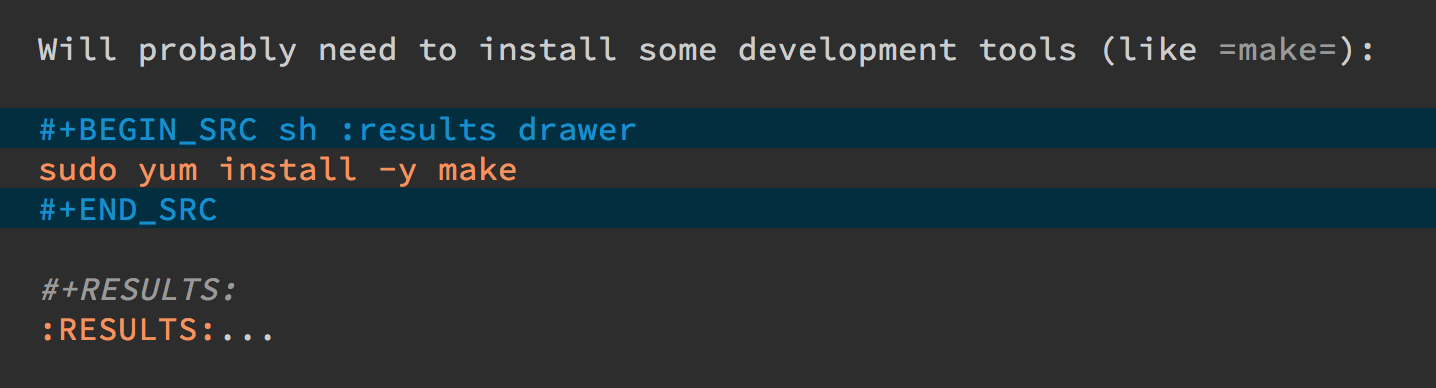
Can you Use the Output?
The results of some commands are often needed for the next command, and I’m sure you love using your mouse to copy and paste part of the output that you want to use.
For instance, I needed a list of an RPM’s dependencies:
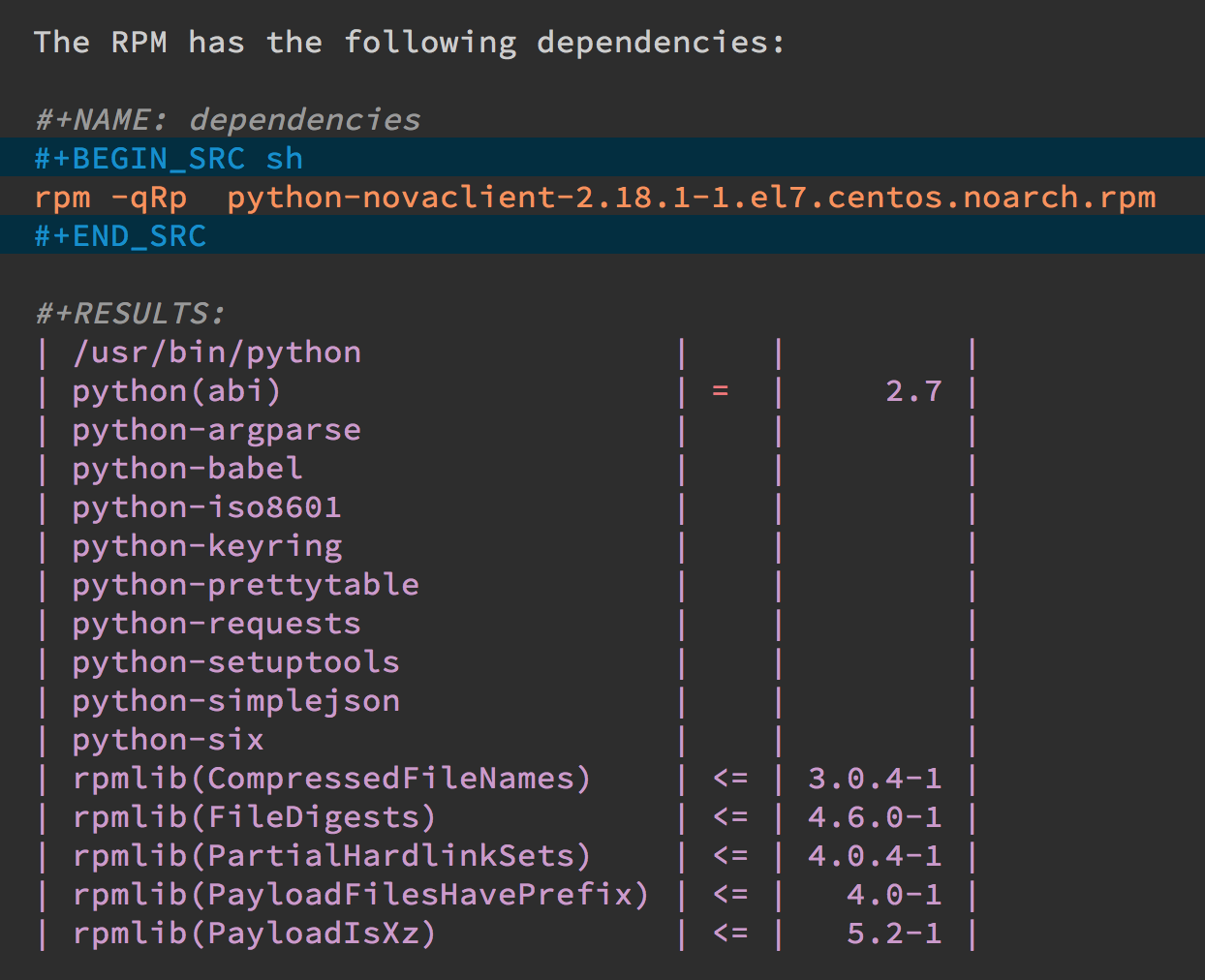
Notice that I named this source block. Also notice how Emacs automatically broke the results up into a table. By default, the output from shell commands are split along newlines and spaces…which is quite useful for me.
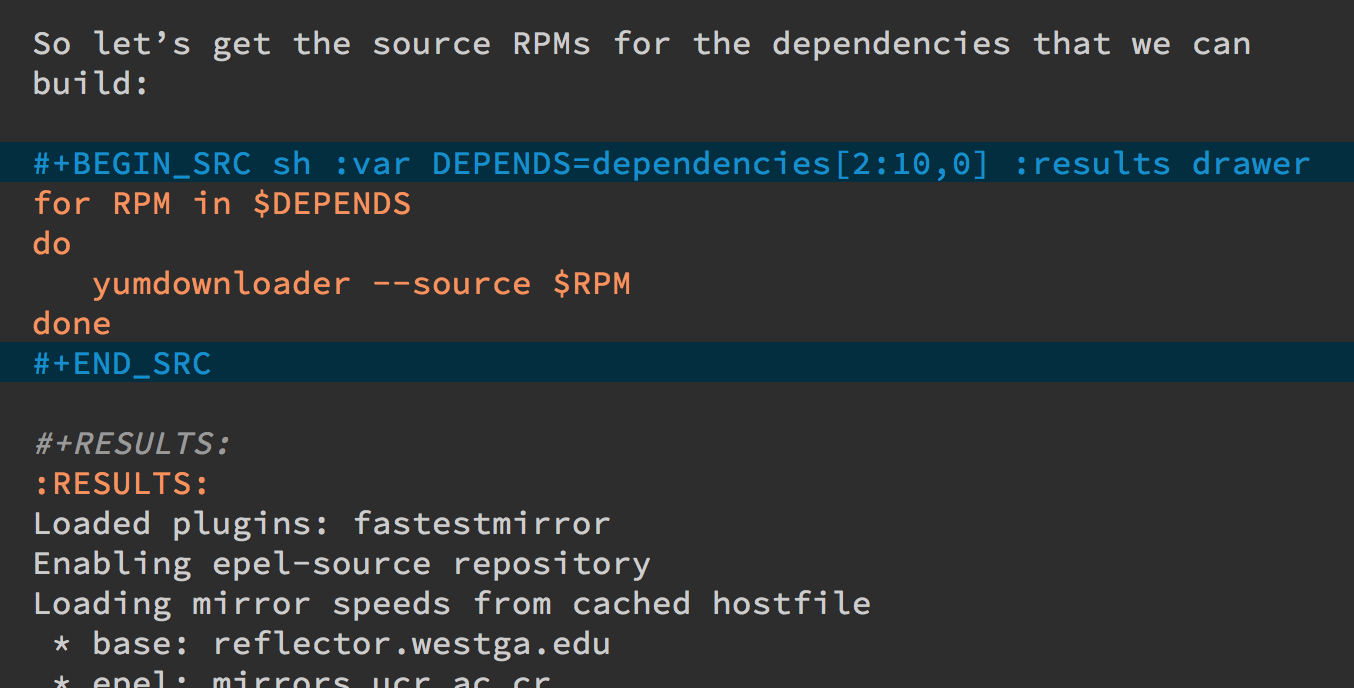
For here is another source block that creates a variable named
DEPENDS that uses rows 2 through 10 of the first column as an
array. I can then download the RPMs I want without any mouse
interaction.
Summary
No, this shouldn’t replace real DevOps automation, but this seems like a good way to take notes before you sit down to write that cookbook.