Doing Pipes the Emacs Way
After a friend of mine mentioned that a shell command sequence through pipes,
a | b | c is same as a nest function call, (c (b (a))) … (or if you don’t like parenthesis, c(b(a)) haha), I noticed another similarity. Without a debugger, the flow of data is invisible, and both become a solid entity.
While this is fine, when developing, you want to see that flow.
The Itch
Let me begin by stating that what follows is an idea…not my go-to approach. However, I daresay, this idea has some legs.
“Hey Howard, can you restart all the OpenStack services on that controller?”
Uh, sure. I’m going to assume that all OpenStack services begin with the word, openstack, so I immediately typed:
for S in $(systemctl --all | grep openstack | sed 's/\.service.*//' | cut -c3-) do systemctl restart $S done
Yes, I know. Hacky, but we do this stuff all the time in the shell, right? Now, if I banged this out the first time, I wouldn’t complain. But that sub-shell sequence within the $(...) took a few iterations to get right.
You know how this goes. Start with an initial command, like systemctl, and gaze at the output, adding one pipe after another, perfecting the last command before moving to the next piped command. With the correct output, we’re ready to move to the for loop.
Since we don’t have a shell command sequence debugger (I don’t even know what that would look like), I want the text that flows from standard out to standard in to be more visible.
A more iterative approach without the constant calling of the initial executable (in my example, systemctl). The typical approach we use is to simply write the output into a file, and work from that.
But I’m in Emacs.
Seems a more Emacsy way would send the output of the systemctl command to a buffer:
UNIT LOAD ACTIVE SUB DESCRIPTION dev-block-7:0.device loaded inactive dead dev-block-7:0.device dev-disk-by\x2dpath-virtio\x2dpci\x2d0000:00:04.0.device loaded active plugged /dev/disk/by-path/virtio-pci-0000:00:04.0 dev-loop0.device loaded active plugged /dev/loop0 dev-vda.device loaded active plugged /dev/vda sys-devices-pci0000:00-0000:00:04.0-virtio1-block-vda-vda1.device loaded active plugged /sys/devices/pci0000:00/0000:00:04.0/virtio1/block/vda/vda1 ...
Then call the keep-lines function (as if it were grep) to keep only lines that match the expression, openstack:
openstack-cinder-api.service loaded active running OpenStack Cinder API Server openstack-cinder-scheduler.service loaded active running OpenStack Cinder Scheduler Server openstack-glance-api.service loaded active running OpenStack Image Service (code-named Glance) API server openstack-heat-api-cloudwatch.service loaded active running OpenStack Heat CloudWatch API Service openstack-heat-api.service loaded active running OpenStack Heat API Service openstack-heat-engine.service loaded active running Openstack Heat Engine Service openstack-keystone.service loaded inactive dead OpenStack Identity Service (code-named Keystone) openstack-nova-api.service loaded active running OpenStack Nova API Server ...
Call keep-lines again, but with a regular expression of active *running, to leave entries of currently running processes. Call replace-regexp (or my personal new favorite, vr/replace) to alter the remaining lines to get that same curated list of services:
openstack-cinder-api openstack-cinder-scheduler openstack-glance-api openstack-heat-api-cloudwatch openstack-heat-api openstack-heat-engine openstack-nova-api ...
I think we’d all agree that if we could easily move the original data into a editor’s buffer, we would like this interactive approach better than attempting pipe prestidigitation. However, once you’ve transformed the data into something more useful, you still need to comsume it.
Often, we’d write the buffers content to a file and then back into the shell… or worse, use the mouse to copy and paste. Gasp.1
But along with good editing features, Emacs can deal with executing commands.
My idea is to make Emacs functions to make both the pipe transformation process and the consumption by executables seamless. For this last part, I can see three solutions to cover 80% of my use cases:
As standard input to another executable or shell command/script, for instance:
$(buffer-contents) | xyz
As a series of argument parameters to an executable, for instance:
xyz $(buffer-contents)
Or a more shell-programmatic way:
$(buffer-contents) | xargs xyz
Calling an executable on each line, similar to what we do with loops, for instance:
for LINE in $(buffer-contents) do xyz $LINE done
To do this, I’m dividing my solution to this wish (and the rest of this essay) in three parts:
- Easily getting the output of a command into a buffer.
- Transforming the data in shell-like ways, Emacs functions, or regular editing, but maybe smooth out the edges.
- Sending the buffer as input to other executable(s).
Finally, I’d like to discuss one possible interface for this. Sounds fun?
Getting Output into Buffers
While the underlying Emacs architecture starts processes and stores the output in buffer, the interface makes too many assumptions. The following pseudo-code shows my idea of running a program asynchronously, but once done, switch to the buffer containing the output, and begin some user interface (see the final version):
(defun piper (command) "Runs a shell command, and puts the output in a buffer. The piper hydra is automatically invoked in order to process the data." (interactive "sCommand: ") (let ((proc (start-process-shell-command "command" "*output*" command))) (set-process-sentinel proc 'piper--process-command)))) (defun piper--process-command (process event) (switch-to-buffer (process-buffer process)) (piper-user-interface))
This runs the command in the background, and calls the sentinel function (er, callback) when done. Quite simple and little more than a wrapper around existing functionality, but makes sure that we get the results from its standard out in a buffer.
My code currently has four entry functions:
piper- Runs a command in local directory and start my user interface on results (see below).
piper-other- Same as
piperexcept it prompts for a directory. piper-remote- Same as above, but it also prompts for a remote host, and executes the command there.
piperfor eshell- with a shell command, but the results overlay the eshell buffer and starts the user interface.
Transforming like a Pipe
The piper-user-interface is simply a Hydra that presents a collection of useful functions grouped into the following categories:
- Movement (the basics of Evil and Emacs keybindings)
- Transforming the data and interacting by executing shell commands (see next section)
- Processing the data as a series of lines (since both
keep-linesandflush-linesdo not have default keybindings). - Standard transformations typical of the shell command output, e.g.
cut
Here is a screenshot of the menu (which I won’t bother to keep up-to-date with the code). Trust me when I say is just gets better with time. ;-)
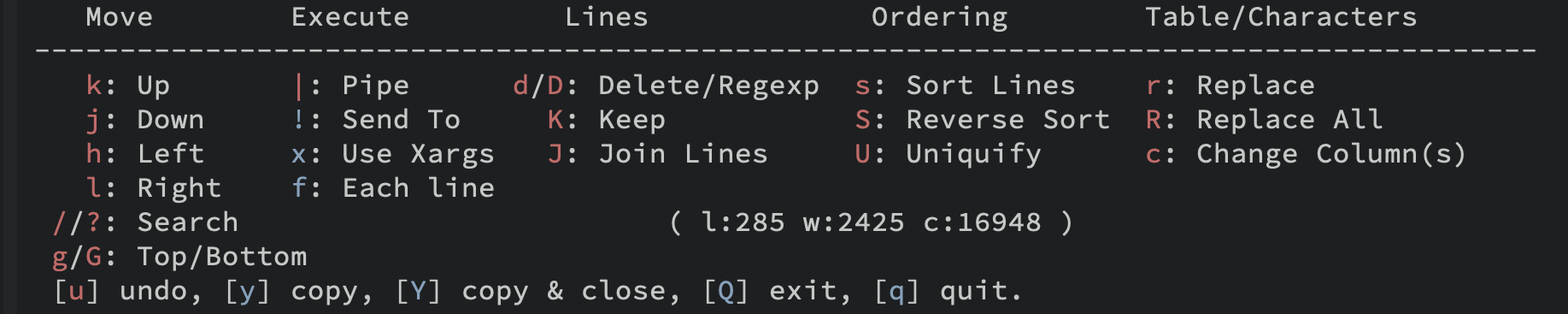
Notice the difference between the red and blue commands. The red commands call a function, but return to this hydra, allowing me to type K a couple of times to run the keep-lines functions for multiple transformations.
Typing a | character, sends the contents of the buffer to a shell command, replacing the buffer with the results. This allows you to essentially type a typical shell command line full of pipes, but watch the data transformations as they happen. Giving me my visibility I mentioned before.
(defun piper-pipe (command) "Replaces the contents of the buffer, or the contents of the selected region, with the output from running an external executable, COMMAND." (interactive "sCommand: ") (save-restriction (shell-command-on-region (point-min) (point-max) command nil t)))
Again, I’ve simplified the above code to make the point, but these functions are just little wrapper functions with default parameters.
Another issue I noticed when using functions like keep-lines and flush-lines, is they only work from the current point to the end of the buffer. So instead of remembering to jump to the start of the buffer, I make a simple wrapper for that too:
(defun piper--function (func) "Call the FUNC function interactively if the region is active, otherwise, go to the beginning of the buffer before calling the function." (save-excursion (unless (region-active-p) (goto-char (point-min))) (call-interactively func)))
So, instead of calling keep-lines, the hydra calls:
(piper--function #'keep-lines)
Buffers as Input
After transforming the data in the buffer (either through repeated calls to shell commands or by normal Emacs functions), I want to do something final with that data. For instance, typing Y will copy the contents of the buffer into the clipboard and close the window.
Along with the | and ! keys that send the buffer data to a shell command as standard input, the other two use cases mentioned before, are calling xargs to put each line in the buffer as different parameters (see the x keybinding), and the for..loop that calls a shell command with each line as a parameter (the f keybinding).
The for … loop usually appends the line to the end of the shell command, e.g.
for LINE in ${BUFFER_CONTENTS} do ${SHELL_COMMAND} $LINE done
The f behaves just like that, where each line in the buffer is appended to a shell command. But what if you need to embed the buffer line in the middle of the shell command? The find command allows that with its -exec parameter, where it replaces {} with the filename. When the f command encounters a {} as a shell command’s parameter, it replaces it with the line.
For instance, if I had a buffer with the contents:
one fish two fish red fish blue fish
Hit the f and typed:
echo start {} and end
I would have a new buffer containing:
start one fish and end start two fish and end start red fish and end start blue fish and end
Summary
This essay is little more than a shift in thinking than any revolutionary idea. Also my code, being simple function wrappers, isn’t really worth stealing (but you can).
However, I feel like I wrote this essay to clarify my own thoughts, and that my written examples and pseudo-code implementations, may not helpful to you, gentle reader. Perhaps, I need to make some nifty swell animations to demonstrate this, since this idea has merit, and I would like to brainstorm with others about it.
Older Idea: Zipping Files
Once upon a time, tar did only a single thing. Now, it does that stuff plus everything else, combining find, compression, and starting your coffee pot. However, the dizzying collection of options can be daunting. Personally, when I have a subset of files, I often use find -type f to view the actual files that to include in the archive.
/Users/howard.abrams/work/wpc4/wpc/monitoring/.flake8 /Users/howard.abrams/work/wpc4/wpc/monitoring/.dir-locals.el /Users/howard.abrams/work/wpc4/wpc/monitoring/artifacts/wpc-monitoring-scripts-0.1.151-1.noarch.rpm /Users/howard.abrams/work/wpc4/wpc/monitoring/monitoring.spec /Users/howard.abrams/work/wpc4/wpc/monitoring/.DS_Store /Users/howard.abrams/work/wpc4/wpc/monitoring/src-python/.flake8 ... /Users/howard.abrams/work/wpc4/wpc/monitoring/.pyenv/man/man1/nosetests.1 /Users/howard.abrams/work/wpc4/wpc/monitoring/.pyenv/.Python /Users/howard.abrams/work/wpc4/wpc/monitoring/.pyenv/bin/convert-json /Users/howard.abrams/work/wpc4/wpc/monitoring/.pyenv/bin/jsondiff ...
Oh, I certainly don’t want to include the .pyenv virtual environment for Python. At the shell, we would continually issue calls to find with options like -prune .pyenv and -prune .git, etc. Using less to visually inspect the list.
And if prune didn’t work, we’d pipe to grep.
However, a more Emacsy way is to issue a C-u M-! on our original find command, and then use the output buffer to issue a series of calls to keep-lines and flush-lines until our buffer has the curated list of files:
/Users/howard.abrams/work/wpc4/wpc/monitoring/src-python/requirements.txt /Users/howard.abrams/work/wpc4/wpc/monitoring/src-python/tests/test_check_heat_resources.pyc /Users/howard.abrams/work/wpc4/wpc/monitoring/src-python/tests/test_reporter.py /Users/howard.abrams/work/wpc4/wpc/monitoring/src-python/tests/test_contrail_processes_check.py /Users/howard.abrams/work/wpc4/wpc/monitoring/src-python/tests/test_check_flows.pyc /Users/howard.abrams/work/wpc4/wpc/monitoring/src-python/tests/support_functions.py /Users/howard.abrams/work/wpc4/wpc/monitoring/src-python/tests/test_check_glance_images.pyc /Users/howard.abrams/work/wpc4/wpc/monitoring/src-python/tests/test_check_cluster_health.pyc /Users/howard.abrams/work/wpc4/wpc/monitoring/src-python/tests/wpcchecks/check_all_capacity_test.py ...
Oh wait, we don’t want to compiled Python files … M-x flush-lines:
Flush lines containing match for regexp: \.pyc$
That’s better.
/Users/howard.abrams/work/wpc4/wpc/monitoring /Users/howard.abrams/work/wpc4/wpc/monitoring/src-python/requirements.txt /Users/howard.abrams/work/wpc4/wpc/monitoring/src-python/tests /Users/howard.abrams/work/wpc4/wpc/monitoring/src-python/tests/test_reporter.py /Users/howard.abrams/work/wpc4/wpc/monitoring/src-python/tests/test_contrail_processes_check.py /Users/howard.abrams/work/wpc4/wpc/monitoring/src-python/tests/support_functions.py /Users/howard.abrams/work/wpc4/wpc/monitoring/src-python/tests/wpcchecks /Users/howard.abrams/work/wpc4/wpc/monitoring/src-python/tests/wpcchecks/check_all_capacity_test.py /Users/howard.abrams/work/wpc4/wpc/monitoring/src-python/tests/wpcchecks/check_compute_capacity_test.py /Users/howard.abrams/work/wpc4/wpc/monitoring/src-python/tests/wpcchecks/check_undead_test.py ...
Now, we can select the buffer and issue C-u M-|
and enter: xargs tar --create --file monitoring.tar
This approach is cummulatively interactive, where re-running the command with variations on the pipe if fine if all the executables are quick, have no side-effects, and is easily built up. The obvious downside is knowing all of these commands and keystrokes.
But this is Emacs, where we can easily solve that problem.
The question I’ve been wrestling is exactly how. I have finally settled on a hydra where I group helpful functions:
- Moving around using vi-like keys.
- Executing shell commands with the contents of the buffer.
- Manipulating the buffer as a series of lines, ala
grep. - Manipulating the buffer as a table, ala
cut.
Footnotes:
If I was to be brutally honest, my biggest gripe with our modern day terminals and shells is that we still resort to the mouse to copy/paste textual data to other GUI applications. And don’t you dare tell me you don’t need to do this, because I see your screen with your fancy browser.






