Introduction to Literate Programming
Recently, I re-stumbled on the idea of literate programming while leveling up with the Babel project (part of Emacs’ org-mode), and thought I would share my perspective (and some of my tools).
Back in 1984, Donald Knuth wrote:
Let us change our traditional attitude to the construction of programs: Instead of imagining that our main task is to instruct a computer what to do, let us concentrate rather on explaining to human beings what we want a computer to do.
He had been playing around with the idea that a “program” shouldn’t be a bunch of computer instructions, but more like literature. He called his approach, literate programming:
The practitioner of literate programming can be regarded as an essayist, whose main concern is with exposition and excellence of style. Such an author, with thesaurus in hand, chooses the names of variables carefully and explains what each variable means. He or she strives for a program that is comprehensible because its concepts have been introduced in an order that is best for human understanding, using a mixture of formal and informal methods that reinforce each other.
After introducing the concept in a white paper, he explained it by publishing an example of how the source code would be written.
Essentially, you describe your program in prose with inserted bits of code. A macro program would then write the code blocks out into a source code file (called tangling) and create a published document of both the prose and the code formatted for reading (called weaving).
What happened to his concept? Perhaps this process was a bit too much writing for most engineers, who view code comments as unnecessary, oversized baggage that needs to be maintained.
However, Java’s Javadoc, Doxygen, Docco and other similar projects that can extract an API from the comments of the source code could be viewed as a step toward literate programming. Haskell has a partial implementation built into the compiler so that it doesn’t require a special comment syntax or an external macro system.
What most of these systems lack is that the code, not the logic, drives the presentation order. For instance, many languages require imports, variable definitions and functions to be declared before they are used. Knuth’s original “WEB” program allowed a code block to refer (include) another code block in no particular order… you could describe your code in any order that made the most sense.
Best Use Cases
I’ve found the best uses for literate programming (LP) are for languages that are:
- Succinct (notice I didn’t say cryptic)
- New (not every team member knows everything), and
- References or includes other languages (like SQL)
However, any sufficiently complicated problem or exploration could benefit from an LP approach.
Needed Tools
I have found that to correctly do literate programming, you need the following:
- A good editor that can deal with code
- A good editor that can deal with prose
- A tool to identify and separate the source code blocks
- A tool to connect (include) one code blocks in another code block
- A way to tangle the source code out to more than one file (Note: this allows you to keep your code and tests together)
- A way to evaluate source code blocks
- A process to create a literate programming document for others to read
Consequently, I have found that using Emacs, with org-mode and its Babel project is nearly ideal.
What does it look like to work this way?
Screen-shots
Here are a few screen-shots of my Emacs environment showing an example of working through the Coin Change Kata in Clojure (but including a snippet of the solution in Scala):
Notice how the source code can have embedded hyperlinks to background or notes:
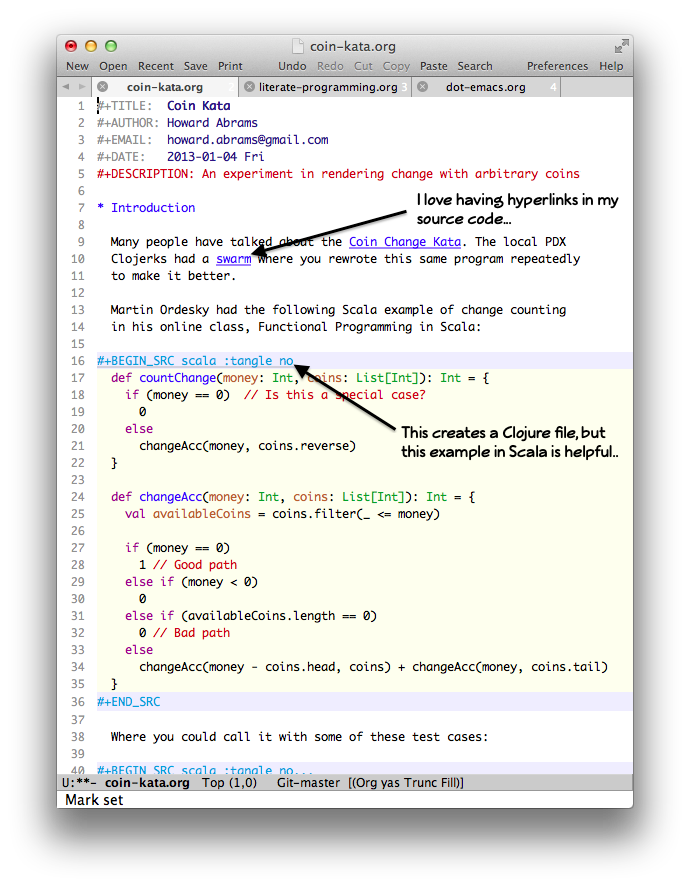
Code blocks can be executed/evaluated directly in the file, and the results can be re-inserted as “text” back into the file, which can then be assigned as a data variable for another code block…which may be code in a different language from the first.
Snaking data through code in this way is for illustrative purposes, which is different than the code written to the final source code files.1
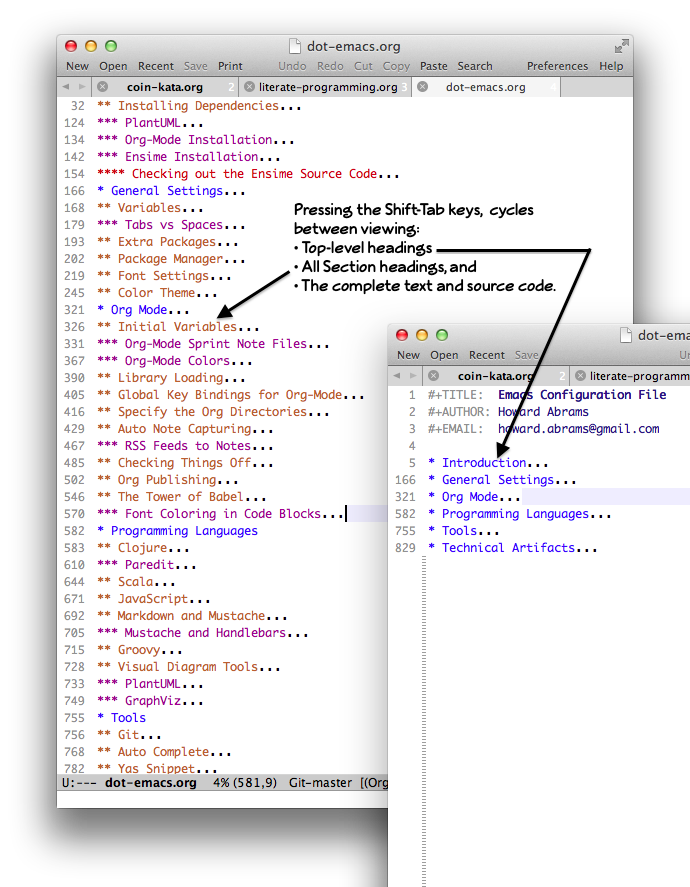
Another nice feature of org-mode is dividing your program into
actual sections that can be collapsed:
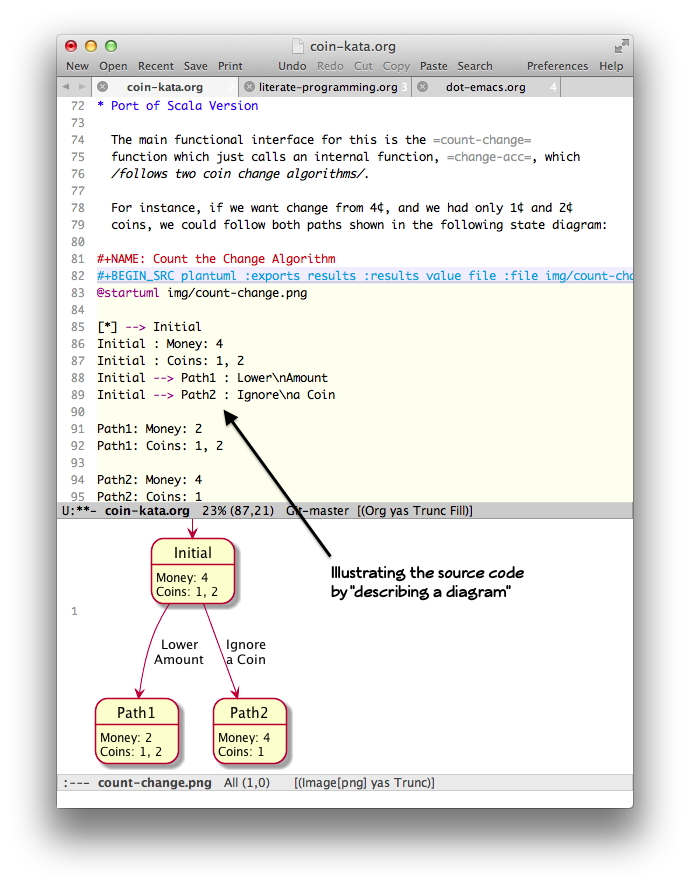
Some code blocks can contain Graphviz or PlantUML instructions, which can serve to illustrate the code, and the diagrams can be embedded in the produced documentation:
Example
In the example below, I begin with a literate program formatted
using org-mode, and then render the code file, as well as export
a readable verison to HTML:
Many people have talked about the Coin Change Kata, as a way to practice our coding craft. I thought it would be fun to try it in a literate way, and this is the results. I suggest viewing the tangled web page first.
<style type=“text/css”> .center { margin-left: auto; margin-right: auto; } .center td { text-align: center; vertical-align: top; } .center a { border: none; text-weight: bold; } .arrow-cell { font-size: 200%; background: white; } .box-cell { font-size: 110%; border: 2px solid #545454; padding: 8px; } </style>
<table class=“center”> <tr><td colspan=“3” class=“box-cell”> <a href=“coin-kata.org”>coin-kata.org</a> </td></tr> <tr><td class=“arrow-cell”> ↓ </td><td></td> <td class=“arrow-cell”> ↓ </td></tr> <tr><td class=“box-cell”> <a href=“coin-kata.html”>coin-kata.html</a> </td> <td> </td> <td class=“box-cell”> <a href=“coin-kata.clj”>coin-kata.clj</a> <a href=“coin-kata-tests.clj”>coin-kata-tests.clj</a> </td></tr></table>
In this example, my literate file included both the solution code as well as the tests (having them side-by-side like can be informative). The tangling process separated it into two separate source code files.
Summary
Should all programs be written in such a style?
A couple years after Knuth officially published his literate programming ideas, he published an example in Jon Bentley’s “Programming Pearls” column [Communications of the ACM 29, 5 (May 1986), 364-3691]. Doug McIlroy added a rebuttal where he boiled Knuth’s example into a single (now famous) shell command:
tr -cs A-Za-z '\n' | tr A-Z a-z | sort | uniq -c | sort -rn | sed ${1}q
McIlroy invented the shell pipe as well as many of those command line tools. He’s quoted as saying:
A wise engineering solution would produce—or better, exploit—reusable parts.
His example proved his point. However, given a complex problem without the necessary components, perhaps composing your initial solution in a literate program is helpful?
Further reading:
- Introduction to org-mode’s Babel Project for teaching Emacs to do Literate Programming
- Reference material for the Babel Project
- More Shell, Less Egg is a good historical essay on this subject
- Where have all the Literate Programmers gone?
Footnotes:
If you understood this paragraph, you would have achieved a sort of literate programming satori, however, I doubt that my prose sufficiently explains this concept.
Check out my essay on Literate Devops for better examples.






